Каталог статей
| Главная » Статьи » S3DecoderLib |
|
S3DecoderLib: Приложение 5. Декомпрессия сжатых блоков DBPF2
|
|
Приложение 5: Декомпрессия сжатых блоков DBPF2 [ Стабильный билд • Описание формата • Sims3: DBPF (eng) • Sims3: DBPF/Compression ]
Програмный модуль и версия DBPF2Decoder.pas, rev.130517Замечание В оригинальном (английском) руководстве есть несколько моментов, например, порядок записей в заголовке, которые не совсем (а на самом деле вообще никак) ни согласуются с реальными данными. Краткий обзор Идея, положенная в сжатие данных – повторное использование предварительно декодированных данных. Так, например, если слово "heureka" встречается дважды в файле, то использование вместо второго вхождения ссылки на первое позволяет сократить занимаемое место. Сжатие выполняется с использованием определенных управляющих символов, которые задают три вещи: - сколько байт должны быть непосредственно перенесены к распакованным данным; - сколько байт должны быть считаны из уже распакованных данных и дописаны к ним в конец; - откуда читаются уже распакованные данные при их копировании;
Описание алгоритма Алгоритм декомпрессии данных состоит в следующем: 1. Читаем заголовок записи (1), он имеет следующий формат: 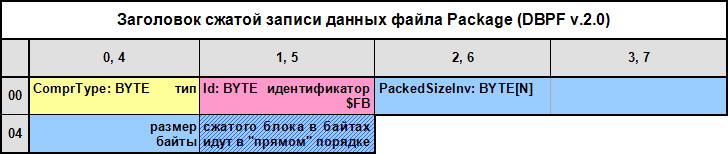
Или в виде типа данных (0): type TDBPF2PackedRecordHeader = packed record ComprType: byte; Id: byte; case Integer of 0: (PackedSize: DWORD;); 1: (PackedSizeBuf: packed array [0..3] of Byte); end; ComprType: BYTE – тип сжатого блока, определяет используемый алгоритм сжатия, при ComprType = $10, $40 параметр PackedSizeBuf имеет размер 3 байта, при $80 – 4 байта, что позволяет хранить сжитые данные объемом до 16 Мб; Id: BYTE – идентификатор сжатого блока, должен быть $FB; PackedSize: DWORD – размер сжатых данных, из-за того, что байты размера данных в заголовке идут в "прямом" порядке (т.е. младший байт по младшему адресу), а в PC наоборот и размер может меняться, то удобнее читать его в виде массива байт PackedSizeBuf: packed array [0..3] of byte (2);
2. После заголовка записи (со смещением 5 или 6 байт, в зависимости от типа сжатого блока) лежат непосредственно данные, соответственно их размер (len) на 5 или 6 байт меньше полного размера блока. Далее в цикле, пока не все данные распакованы (3): - читаем первый байт управляющего символа (4); - в зависимости от того, какой это управляющий символ, читаем дополнительно его 0..3 байта (5); - определяем какие данные и откуда должны копироваться (6); - копируем 0..n байт данных, которые должны бать непосредственно перенесены к распакованным данным (7); - копируем 0..n байт данных, которые должны быть считаны из уже распакованных данных и дописаны к ним в конец (8);
Управляющие символы Существует четыре типа управляющих символов. Они используются с различными ограничениями на то, сколько байт данных читается и как далеко от конца потока они могут читаться. Следующие термины будут применяться в их описании: - первичный поток – поток содержащий файл, с которым ведется работа в данный момент, вторичный поток – поток, содержащий декодированную запись; процедура декодирования собственно и состоит в выборке данных из первичного потока по определенным правилам (управляющим символам) и заполнении ими (добавлении в конец) вторичного потока. - numplain (Num plain text) – число байт, которые непосредственно копируются из конца первичного потока во вторичный; - numcopy (Num to copy) – число уже декодированных байт, которые копируются с определенной позиции вторичного потока в его конец; - offset (Copy offset) – смещение во вторичном потоке откуда копируются данные с конца потока, смещение 0 соответствует последнему декодированному байту, 1 – байте перед ним; - cc[N] – N-ный байт заголовка блока с управляющими символами (нумерация начинается с 0), соответственно cc[0] – первый байт; - биты управляющего символа: * p – numplain; * c – numcopy * o – offset; * i – идентификатор символов, в отдельности не существует, т.к. представляет собой диапазон значений первого байта заголовка блока; Замечание: Иногда может случиться, что управляющий символ потребует, например, что необходимо скопировать 10 символов 5 с конца потока. Ясно, что невозможно прочитать более чем 5 символов до того как будет достигнут конца буфера. Решение – читать и записывать по одному символу. Каждый раз, когда вы читаете символ, вы копируете это в конец таким образом увеличивая размер потока. Таким образом, даже offset = 0 корректен и приводил бы к дублированию последнего символа несколько раз – это используется, например, при сжатии строк имитирующих линии и состоящих из повторяющихся символов тире.
CC[0] - $00 .. $7F – копирует 0..3 байта данных из первичного потока во вторичный, затем копирует 3..10 байт из вторичного потока во вторичный 
CC[0] - $80 .. $BF – копирует 0..3 байта данных из первичного потока во вторичный, затем копирует 4..67 байт из вторичного потока во вторичный 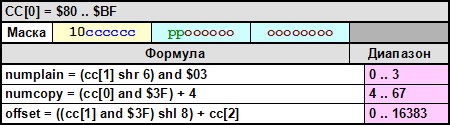
CC[0] - $C0 .. $DF – копирует 0..3 байта данных из первичного потока во вторичный, затем копирует 5..1028 байт из вторичного потока во вторичный 
CC[0] - $E0 .. $FB – копирует 4..112 байт данных из первичного потока во вторичный 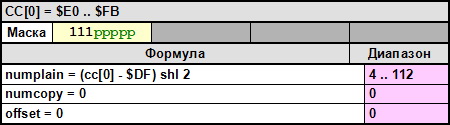
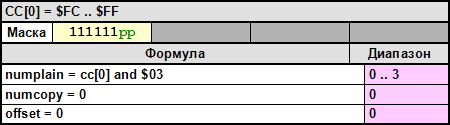
CC[0] - $FC .. $FF – копирует 0..3 байта данных из первичного потока во вторичный, блок сжатых данных должен заканчиваться этим управляющим символом, при отсутствии данных последним символом должен быть $FC. Отсутствие завершающей последовательность приводит к краху игры при попытки загрузки неверного блока.
Реализация на Pascal Реализация декомпрессии записей формата DBPF2 содержится в файле DBPF2Decoder.pas
Метод Decode вызывается при получении данных записи в виде потока: procedure TDBPF2Item.Decode(AStream: TStream); // декодирует данные записи begin FreeStream; if AStream=nil then exit; if cardinal(FStream)=$FFFF then begin // если запись удалена AStream.Free; // освобождаем вторичный поток exit; end; FStream:= AStream; FOwner.FStream.Seek(FOffset, soFromBeginning); // встали на начало записи if FCompressed=0 then FStream.CopyFrom(FOwner.FStream, FPackedSize) else UnCompress; end;Если блок сжат, то защищенный метод UnCompress вызывается автоматически из Decode: procedure TDBPF2Item.UnCompress; var // определение переменных cc: packed array[0..3] of byte; i: integer; cursize, numplain, numcopy, offset: integer; fromoffset: integer; len: integer; buf: packed array [0..32] of DWORD; h: TDBPF2PackedRecordHeader; begin with FOwner.FStream do begin ReadBuffer(h, 2); // (1) if h.Id<>$FB then // если неверный заголовок блока, raise EDBPF2HeaderError.Create(csUnCompressionIdError); // то генерим эксепшен if h.ComprType=$80 then begin // если тип блока 0x80, то размер 4 байта ReadBuffer(h.PackedSizeBuf[3], 1); len:= FPackedSize-6 end else begin // иначе три h.PackedSizeBuf[3]:= 0; len:= FPackedSize-5 end; ReadBuffer(h.PackedSizeBuf[2], 1); ReadBuffer(h.PackedSizeBuf[1], 1); ReadBuffer(h.PackedSizeBuf[0], 1); // байты идут в прямом порядке, читаем по одному (2) if h.PackedSize<>FMemSize then // если размер не совпадает с индексной таблицей raise EDBPF2HeaderError.Create(csUnCompressionSizeError); // то генерим эксепшен cursize:= 0; while len>0 do begin // len содержит число еще не разжатых байт (3) ReadBuffer(cc[0], 1); dec(len); // (4) // (5, 6) if cc[0]>=$FC then begin // 0xFC - 0xFF numplain:= cc[0] and $03; if numplain>len then numplain:= len; numcopy:= 0; offset:= 0; end else if cc[0]>=$E0 then begin // 0xE0 - 0xFB numplain:= (cc[0]-$DF) shl 2; numcopy:= 0; offset:= 0; end else if cc[0]>=$C0 then begin // 0xC0 - 0xDF ReadBuffer(cc[1], 3); dec(len, 3); numplain:= cc[0] and $03; numcopy:= ((cc[0] and $0C) shl 6) + cc[3] + 5; offset:= ((cc[0] and $10) shl 12) + (cc[1] shl 8) + cc[2]; end else if cc[0]>=$80 then begin // 0x80 - 0xBF ReadBuffer(cc[1], 2); dec(len, 2); numplain:= (cc[1] shr 6) and $03; numcopy:= (cc[0] and $3F) + 4; offset:= ((cc[1] and $3F) shl 8) + cc[2]; end else begin // 0x00 - 0x7F ReadBuffer(cc[1], 1); dec(len); numplain:= (cc[0] and $03); numcopy:= ((cc[0] shr 2) and $07) + 3; offset:= ((cc[0] and $60) shl 3) + cc[1]; end; if (numplain>0) then begin // (7) ReadBuffer(buf, numplain); FStream.WriteBuffer(buf, numplain); inc(cursize, numplain); dec(len, numplain); end; fromoffset:= cursize - (offset + 1); // 0 - это конец потока for i:= 0 to numcopy-1 do begin // (8) FStream.Seek(fromoffset+i, soBeginning); FStream.ReadBuffer(buf, 1); FStream.Seek(0, soEnd); FStream.WriteBuffer(buf, 1); end; inc(cursize, numcopy); end end; if cardinal(cursize)<>FMemSize then raise EDBPF2UnCompressionError.Create(csUnCompressionSizeError); // если размер не совпадает с индексной таблицей, то генерим эксепшен end; | |
| Категория: S3DecoderLib | Добавил: crazylab (28.09.2013) | |
| Просмотров: 1119 |